

1. 软件是什么?能帮你做什么?
1.1 软件简介
AI 图文提取器是一款桌面小工具,专门帮你把图片里的文字自动识别出来,保存成 TXT 文本文件,方便后续:
复制粘贴 到 Word、PPT、Excel 里继续编辑
全文搜索 某个关键词(例如合同中的某条条款)
长期归档:把扫描件里的文字“解放”出来,保存成可编辑文本
你只需要:
选中 图片所在文件夹(支持整批图片,支持子文件夹)
选中 TXT 输出文件夹
填好 接口密钥(API Key),点击“开始”
软件会自动:
逐张调用 AI 视觉识别接口
把识别到的 全部文字 写入到与你图片同名的
.txt文件中文本文件按你指定的 TXT 文件夹组织,方便查看和备份
🔒 隐私说明(重要):
识别需要联网,调用你配置的 AI 接口(例如作者提供的 OpenAI 兼容接口)。
软件本地只会:读取图片文件 → 把识别结果写入 TXT 文件,不会对原始图片做覆盖、修改等操作。
请确保你使用的接口服务可信,并遵守相关法律法规和服务条款。
1.2 适合谁用?
老师 / 教培机构:
批量把试卷、教案、练习册扫描件里的文字提取出来,方便改写、排版、出新题。
办公人士 / 行政 / 法务:
合同、制度、通知扫描件里的文字一键提取,后续在 Word 里修改更方便。
自媒体 / 运营 / 设计:
海量长图、截图里的文案一键提出来,方便改写、做新素材。
个人资料整理爱好者:
笔记截图、书页照片、票据等都能转成文本长期保存。
如果你经常需要 对着图片重新打字,这个软件可以帮你节省大量时间 ⏱️。
2. 界面总览(认识一下主界面)
软件主界面分成三大页签:
「操作」页:
选择图片文件夹、TXT 文件夹
加载文件、开始处理、暂停/继续
查看文件列表、处理进度和统计
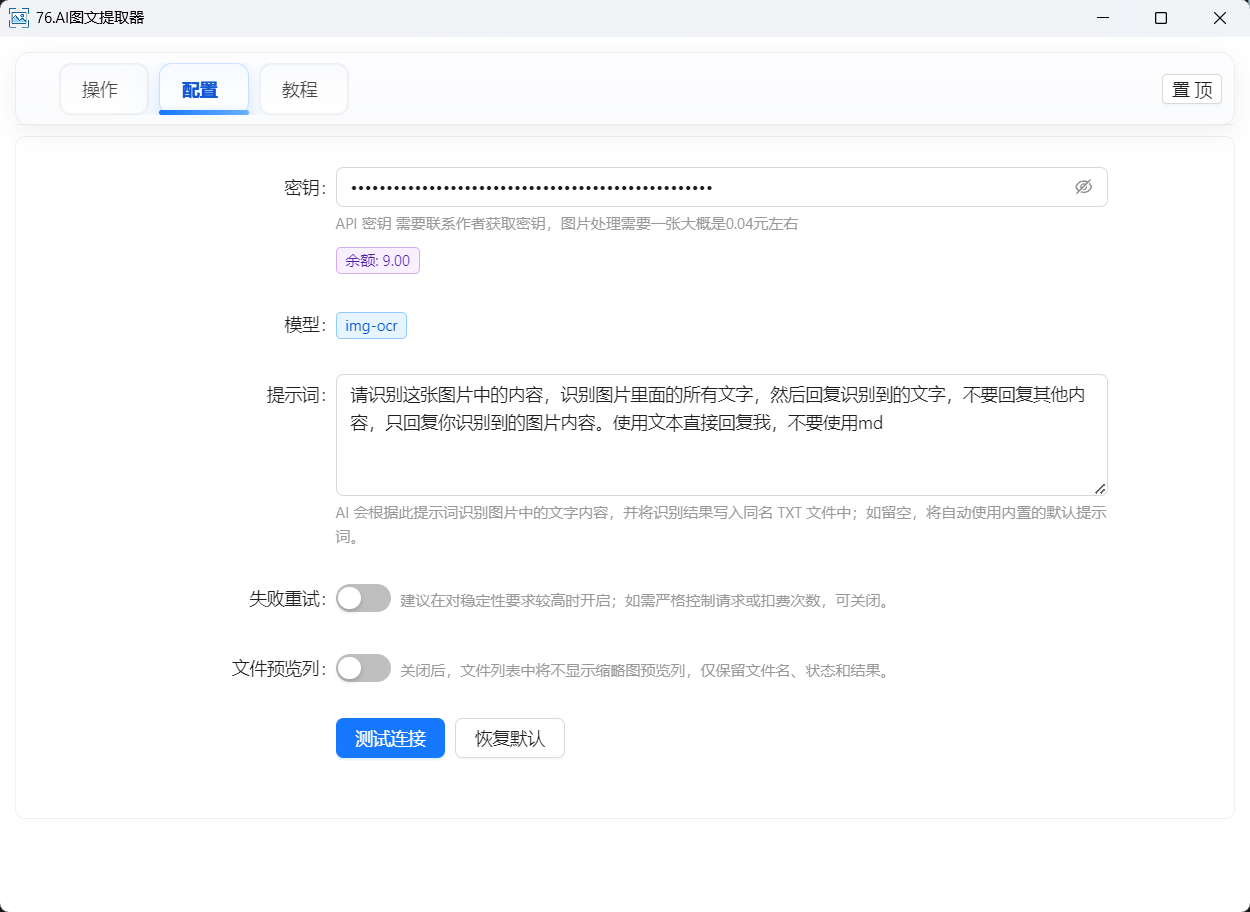
「配置」页:
填写 API 密钥(Key)
设置提示词
是否开启失败重试
是否显示文件缩略图预览列
「教程」页:
软件概述
使用流程、常见问题说明
按钮直达在线完整教程
2.1 顶部标签栏
左侧是三个页签:
操作/配置/教程右上角有一个 「置顶」按钮:
点击后窗口会置顶,方便你一边看文件夹一边操作软件。
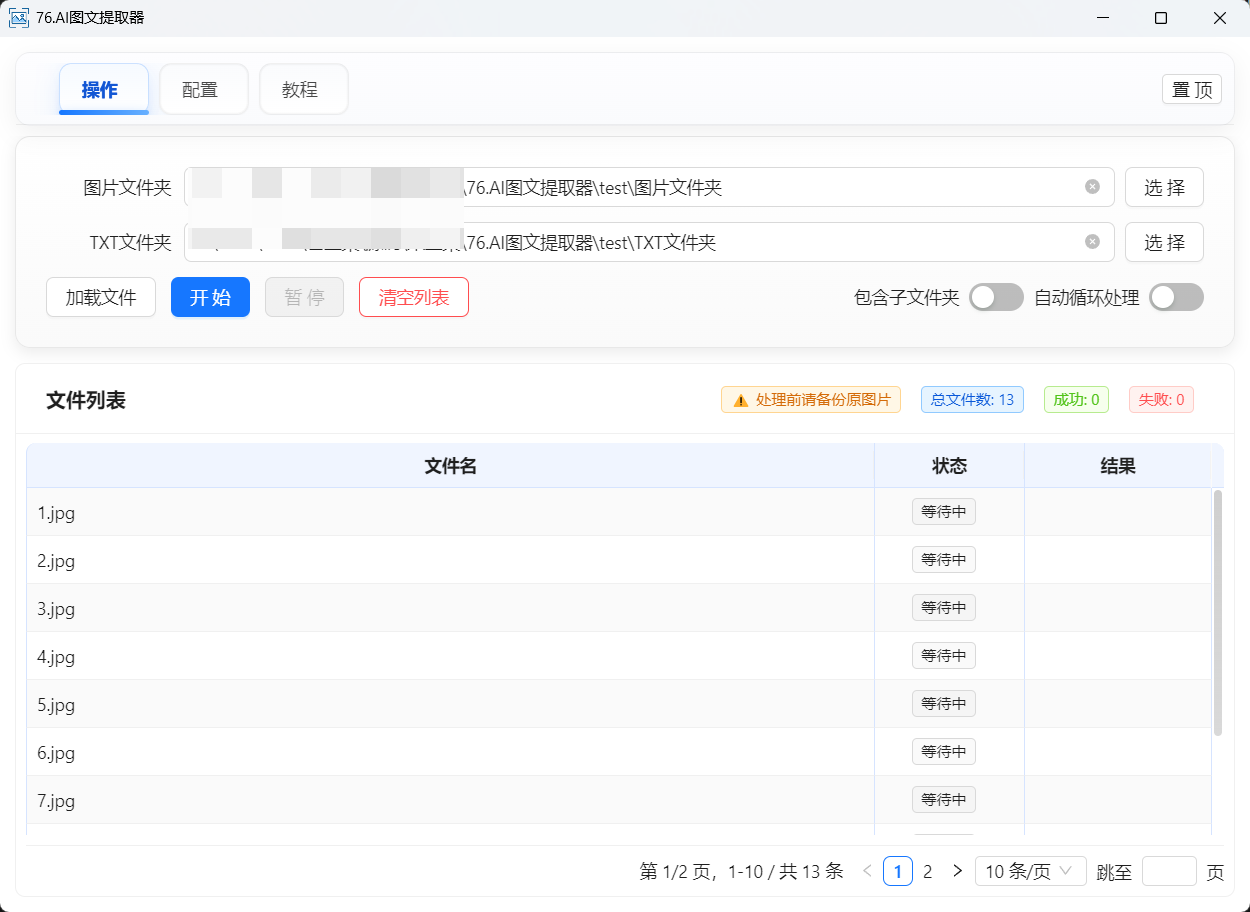
2.2 操作页主要区域
图片文件夹:选择你要识别的图片所在的文件夹
可点击“选择”按钮打开系统对话框
也可以把文件夹直接拖拽到输入框里
TXT 文件夹:选择识别结果要保存到的文件夹
建议提前新建一个空文件夹,例如:
D:\图文提取结果
按钮区:
加载文件:从图片文件夹读取图片列表开始 / 开始自动循环:启动识别暂停 / 继续:处理中途可暂停,再继续清空列表:清空当前文件列表和状态
右侧开关:
包含子文件夹:开:会把子文件夹里的图片一起加载
关:只处理当前文件夹下的图片
自动循环处理:用于“监控某个文件夹,有新图就自动处理”的场景,后文有详细说明。
文件列表 & 统计:
上方会显示:总文件数 / 成功数 / 失败数
下方表格中,每一行是一张图片,对应一个处理状态:
等待中 / 处理中 / 已完成 / 失败
3. 第一次使用:从零开始完整操作一遍
下面以 “把一批 JPG 图片里的文字提取成 TXT 文本” 为例,手把手带你完成一次完整操作。
步骤 1:准备两个文件夹 📁
在任意磁盘(例如
D:)新建两个文件夹:D:\图文提取\图片文件夹D:\图文提取\TXT文件夹
把你要识别的图片复制到
图片文件夹里。支持格式:JPG / JPEG / PNG / GIF / BMP / WebP / SVG / ICO / TIF / TIFF
单张图片大小 ≤ 50MB
小提示:建议先准备 3~5 张图片做测试,确认识别效果和费用都能接受,再往里放大量图片。
步骤 2:配置 API 密钥 🔑
在软件中切换到 「配置」 页。
在“密钥”输入框中,填入你从作者处获取的 API Key。
可选:点击 「测试连接」 按钮:
成功:会弹出“连接成功”的提示。
失败:检查 Key 是否填写正确、网络是否正常。
“模型”一般已经固定为
img-ocr,你无需修改。
⚠️ 识别图片会消耗一定费用(例如每张约 0.04 元,具体以实际接口计费为准)。请合理控制识别数量。
步骤 3:设置提示词(可选)💬
在“配置”页中有一个 「提示词」 文本框:
默认提示词大意是:
“请识别图片中的所有文字,只回复识别到的文字,不要回复其他内容。”
你可以根据需要修改,例如:
“请识别图片中的所有中文与数字,保持原有换行,不要自行增删文字。”
若不清楚如何写,留空或使用默认提示词即可,软件会自动使用内置提示词。
步骤 4:选择图片文件夹和 TXT 文件夹 📂
切换到 「操作」 页。
在“图片文件夹”一行:
点击“选择”按钮
选择刚才的
D:\图文提取\图片文件夹
在“TXT 文件夹”一行:
点击“选择”按钮
选择
D:\图文提取\TXT文件夹
一定要确保两个路径都选对,否则会提示“未选择图片文件夹 / TXT 文件夹”。
步骤 5:加载文件 👀
点击“加载文件”按钮。
稍等片刻,下方“文件列表”中会显示当前文件夹下的所有图片名称。
顶部统计区域会显示“总文件数:X”。
如果勾选了“包含子文件夹”:
会把子文件夹中的图片一起统计进来。
步骤 6:开始处理 🏃
再次确认:
API Key 已填写并通过测试(推荐先测试一次)。
图片文件夹 / TXT 文件夹都已经正确选择。
点击蓝色的 “开始” 按钮:
按钮文案会变为“处理中...”。
列表中的每一行会依次变成“处理中 / 已完成 / 失败”。
处理过程说明:
对每一张图片,软件会:
读取本地图片
编码后发给 AI 识别接口
获取文本结果
在你设置的 TXT 文件夹中,按图片同名 生成一个
.txt文件并写入识别结果
若中途出现网络波动且你在“配置”页开启了“失败重试”,软件会自动进行一定次数的重试。
处理过程中如果需要暂时停一下,可以点击“暂停”;再次点击会“继续”。
步骤 7:查看识别结果 📄
打开你之前选择的
TXT 文件夹(例如D:\图文提取\TXT文件夹)。可以看到多个
.txt文本文件:图片A.jpg→图片A.txt合同第一页.png→合同第一页.txt
用记事本 / Notepad++ / VS Code 等工具打开
.txt文件,就能看到识别出来的全部文字。
如果你对结果不满意,可以:
换一张清晰度更高的图片
调整提示词(例如强调“不要编造内容”)
重新运行一次处理
4. 示例:批量处理一个资料文件夹
假设你有一个资料文件夹:
E:\资料\扫描文件中有 200 张扫描件(试卷、合同、通知等)你希望把所有文字提取出来,方便后续搜索和编辑。
可以这样做:
在
E:\资料下新建文字版文件夹:E:\资料\文字版。在软件中:
图片文件夹:选
E:\资料\扫描文件TXT 文件夹:选
E:\资料\文字版勾选“包含子文件夹”(如果扫描文件中还有子目录)
点击“加载文件”,再点击“开始”。
稍等一段时间后,去
E:\资料\文字版中查看生成的.txt文件。
这样,你就多了一份 可全文检索、可编辑的“文字版资料库” 📚。
5. 进阶功能说明
5.1 自动循环处理(监控文件夹新图片) 🔁
适用场景:
你有一个“待识别图片”文件夹,不定期会有新图片被保存进来(例如扫描仪输出目录、截图工具保存目录)。
希望软件 自动、持续 帮你处理新进来的图片,而不是每次手动点击“开始”。
使用步骤:
正常选好“图片文件夹”和“TXT 文件夹”,并“加载文件”。
在“操作”页右侧勾选:
自动循环处理。点击“开始自动循环”。
软件会:
先处理当前文件列表
每轮处理完成后:
自动清空列表
自动重新加载同一个图片文件夹
如果暂时 没有新图片:
会每隔一段时间(如 30 秒)自动重试加载
停止自动循环的方式:
取消勾选“自动循环处理”,或
点击“暂停”,或
直接关闭软件窗口。
5.2 失败重试机制 🧱
在“配置”页中有一个 「失败重试」 开关:
开启后:
当接口返回网络错误、限流或服务器 5xx 错误等可恢复错误时,软件会 自动重试最多 3 次。
能在网络不稳定时明显提高整体成功率。
关闭后:
每张图片只请求一次,失败就直接标记为“失败”。
⚠️ 注意:开启重试在“失败场景”下会多发几次请求,也就意味着可能多花一点费用。请按自己的稳定性要求和预算权衡。
5.3 文件预览列 🖼️
在“配置”页中可选择是否显示 文件缩略图预览列:
开启:列表中会多一列小缩略图,方便肉眼确认图片内容。
关闭:只显示文件名、状态和结果,适合追求极简和性能的用户。
5.4 包含子文件夹 ✅
位于“操作”页按钮区右侧。
勾选后:
软件会递归遍历你选择的图片文件夹下的所有子目录,将里面的图片一并处理。
不勾选:
只处理当前这一层文件夹下的图片。
6. 常见问题(FAQ)❓
Q1:支持哪些图片格式?单张图片最大多大?
支持格式:
JPG/JPEG/PNG/GIF/BMP/WebP/SVG/ICO/TIF/TIFF单张图片体积:
最大约 50 MB,超过会被视为“图片过大”。
Q2:软件会不会修改或删除我的原始图片?
当前版本只会 读取原图,不会修改、移动或删除你的图片。
识别结果会写入到你指定的 TXT 文件夹中,生成新的
.txt文本文件。为了安全起见,仍然强烈建议你提前做好图片备份。
Q3:识别出来的文字不准确怎么办?
可以从几个方面排查:
图片本身是否:
太模糊 / 分辨率太低
倾斜严重 / 有阴影
提示词是否太模糊:
可以在提示词里强调“请尽量逐字识别,不要编造内容”。
内容本身是否:
含有大量手写字、特殊字体或极端排版(这类内容天生更难识别)。
适当调整提示词、多尝试几种图片样本,能明显改善效果。
Q4:为什么一直提示“未配置 API Key”?
请到“配置”页检查:
是否已经填入完整的 Key
前后是否有多余空格
填完后 按一下回车或点击其他位置,再试一次“测试连接”。
Q5:软件能离线使用吗?
目前 不能离线使用。
图文识别依赖在线 AI 接口,需要稳定网络连接。
Q6:识别结果是保存在云端还是本地?
识别过程在云端(你的 AI 服务商)完成。
最终的识别结果文本是由软件 写到你本地磁盘上的 TXT 文件 中。
7. 使用建议与注意事项 📌
建议一:务必先做小批量测试
先选 3~5 张典型图片跑一轮,确认:
识别质量是否可接受
费用是否在可承受范围
建议二:重要图片请先备份
虽然软件默认不修改原图,但养成备份习惯总是好的。
建议三:按场景规划文件夹结构
例如按“年份 / 项目 / 类型”建立不同的图片与 TXT 文件夹,后期查找会轻松许多。
建议四:保持网络通畅
大批量处理时,尽量在网络稳定的时候执行,能缩短整体耗时并减少失败重试。
8. 遇到问题如何求助?🆘
如果你在使用中遇到:
软件无法启动
一直识别失败
不知道如何配置提示词
想要定制功能(例如支持特定模板、导出为 Word/Excel 等)
可以通过软件中“教程”页里的联系方式(例如作者微信)进行反馈沟通。
感谢使用 AI 图文提取器,祝你从此告别“对着图片慢慢打字”的苦力活!🎉
