

一、软件简介
根据TXT文档内容与提示词AI生成MD文档 是一款桌面应用,核心功能是:
📄 读取 TXT 文件内容 → 🤖 结合你写的提示词发给 AI → 📝 把 AI 返回的内容自动保存成 Markdown(.md)文件
✨ 主要特点
二、你需要准备什么
在使用本软件之前,你需要准备以下 4 样东西:
✅ 1. TXT 文件(待处理的原始内容)
把你要处理的文本内容保存成 .txt 格式,放进同一个文件夹。
例如:
D:\我的资料\待处理\
├── 第一章笔记.txt
├── 第二章笔记.txt
└── 会议记录.txt
✅ 2. MD 输出文件夹
单独创建一个空文件夹,用来存放生成的 Markdown 文件。
例如:
D:\我的资料\输出MD\
⚠️ 建议输出文件夹和 TXT 文件夹分开放,不要设为同一个。
✅ 3. AI 接口信息
你需要有一个 OpenAI 兼容的 AI 接口,包含以下三项信息:
💡 支持 OpenAI、DeepSeek、月之暗面(Kimi)、通义千问等兼容 OpenAI 格式的接口。
✅ 4. 提示词文件
把你的提示词保存成一个文件,支持格式:.txt、.md、.doc、.docx
提示词文件示例(prompt.txt):
你是一名专业的文档整理助手。
请将用户提供的笔记内容,整理成结构清晰、层次分明的 Markdown 文档。
要求:
- 提取主要知识点,使用二级标题(##)分类
- 重要概念加粗显示
- 适当添加 > 引用块突出关键信息
- 保持内容完整,不要省略任何重要信息
三、界面总览
软件共有 3 个页面,通过顶部标签切换:
┌──────────────────────────────────────────────────────┐
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │ 操作页 │ │ 配置页 │ │ 教程页 │ │
│ └────────┘ └────────┘ └────────┘ │
├──────────────────────────────────────────────────────┤
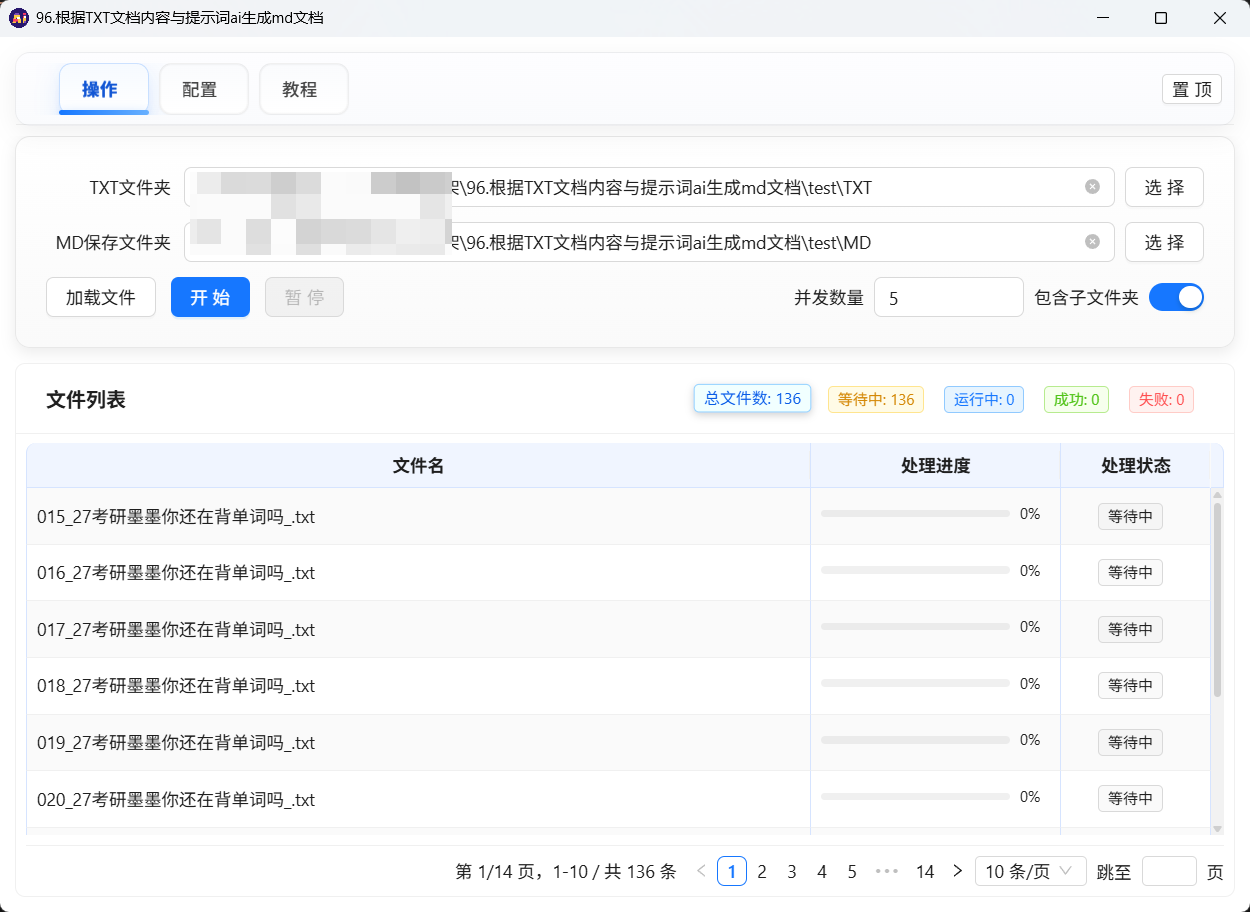
│ 【操作页】 │
│ TXT文件夹:[_______________] [选择文件夹] │
│ MD保存到:[_______________] [选择文件夹] │
│ [加载文件] [开始] [暂停] 并发数: [2] │
│ │
│ 文件名 进度 状态 │
│ 第一章.txt ████░░░░░░ 处理中 │
│ 第二章.txt ░░░░░░░░░░ 等待中 │
└──────────────────────────────────────────────────────┘
页面说明
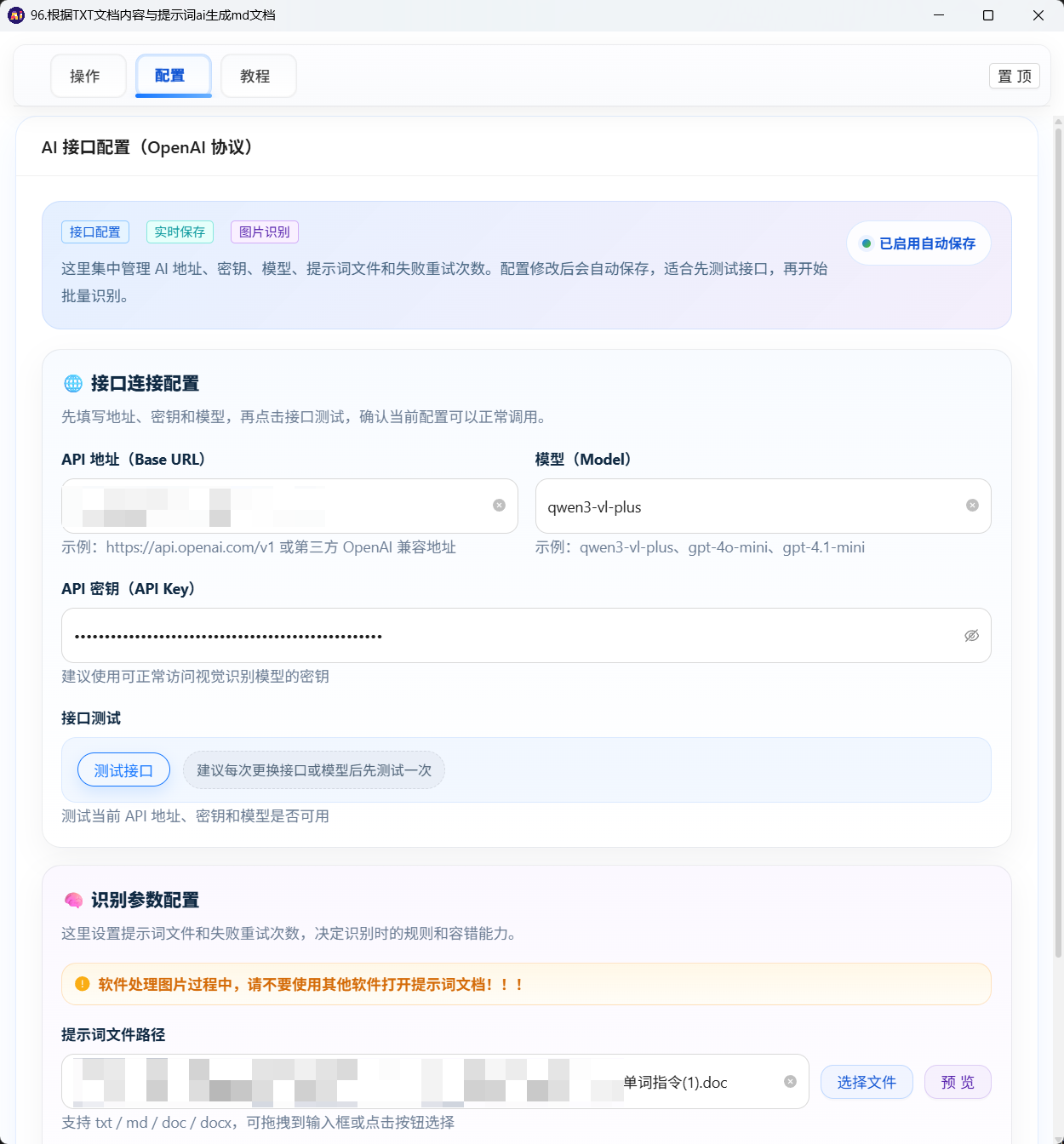
四、第一步:配置 AI 接口
点击顶部 「配置页」 标签,进行以下设置:
4.1 填写 AI 接口信息
4.2 测试接口
填写完成后,点击 「测试接口」 按钮:
✅ 绿色提示「连接成功」:可以继续下一步
❌ 红色提示「连接失败」:检查 API 地址、密钥、模型名称是否正确
💡 常见接口地址参考:
OpenAI 官方:
https://api.openai.comDeepSeek:
https://api.deepseek.com月之暗面 Kimi:
https://api.moonshot.cn通义千问:
https://dashscope.aliyuncs.com/compatible-mode
4.3 选择提示词文件
在配置页点击 「选择提示词文件」,找到你准备好的提示词文件。
选择后可以点击 「预览提示词」 查看文件内容,确认提示词加载正确。
4.4 其他配置项
五、第二步:选择文件夹与提示词
回到 「操作页」:
5.1 选择 TXT 文件夹
点击 「TXT文件夹」 旁边的 「选择文件夹」 按钮,选择存放 TXT 文件的文件夹。
也可以直接把文件夹拖拽到输入框上。
ℹ️ 软件会自动过滤掉「已完成」子文件夹,避免重复处理。
5.2 选择 MD 输出文件夹
点击 「MD保存到」 旁的 「选择文件夹」 按钮,选择生成的 MD 文件要保存到哪里。
如果该文件夹不存在,软件会自动创建。
六、第三步:加载文件并开始处理
6.1 加载文件
点击 「加载文件」 按钮,软件会扫描 TXT 文件夹中的所有 .txt 文件并显示在列表中。
💡 支持 递归加载(勾选「包含子文件夹」),可以加载文件夹内所有子文件夹中的 TXT 文件。
6.2 开始处理
确认文件列表无误后,点击 「开始」 按钮。
软件会按照并发数,同时处理多个文件,每个文件的处理流程为:
读取 TXT 内容
↓
读取提示词文件内容
↓
将「提示词 + TXT 内容」发送给 AI
↓
接收 AI 返回的 Markdown 内容
↓
写入同名 .md 文件到输出文件夹
↓
将原 TXT 文件移动到「已完成」子文件夹
↓
该文件状态变为「已完成」✅
6.3 暂停与继续
点击 「暂停」:当前正在处理的文件会完成后暂停,新文件不再开始
点击 「继续」:从暂停处继续处理
七、处理过程说明
7.1 进度状态说明
7.2 文件归档逻辑
成功处理后,原 TXT 文件会被自动移动到:
原TXT所在文件夹/已完成/原文件名.txt
例如:
处理前:D:\资料\待处理\第一章.txt
处理后:D:\资料\待处理\已完成\第一章.txt
生成的MD:D:\资料\输出MD\第一章.md
下次点击「加载文件」时,「已完成」文件夹内的文件会自动被过滤掉,不会重复处理。
7.3 失败重试机制
如果 AI 调用失败(网络超时、接口报错等),软件会自动重试,重试次数由配置页的「AI 重试次数」决定。
重试全部失败后,该文件会标记为「失败」,并将错误信息写入 error.log 文件。
八、提示词编写指南(含示例)
提示词是本软件最核心的部分,提示词写得好,输出质量就高。以下是几个实用示例:
📌 示例一:课堂笔记整理
场景: 把杂乱的课堂笔记整理成有结构的 Markdown
提示词(prompt.txt):
你是一名专业的学习笔记整理助手。
请将以下课堂笔记内容整理成结构清晰的 Markdown 文档,要求:
1. 使用二级标题(##)按主要知识点分类
2. 核心概念用加粗(**概念**)标注
3. 定义、公式等使用 > 引用块展示
4. 如有步骤性内容,使用有序列表(1. 2. 3.)
5. 保持原文信息完整,不要遗漏任何内容
6. 在文档开头添加一级标题(#)作为文档名
输入 TXT 内容(第一章.txt):
今天讲了牛顿第一定律 就是惯性定律 物体不受力或合力为零时保持静止或匀速直线运动
还讲了惯性的概念 惯性是物体保持运动状态不变的性质 质量越大惯性越大
举例子 推车 空车好推 重车难推
AI 生成的 MD 输出(第一章.md):
# 第一章:牛顿运动定律
## 牛顿第一定律(惯性定律)
> 物体不受力或合力为零时,保持**静止**或**匀速直线运动**状态不变。
## 惯性
**惯性**是物体保持自身运动状态不变的性质。
> 质量越大,惯性越大。
### 生活实例
- 空车容易推动(质量小,惯性小)
- 重车难以推动(质量大,惯性大)
📌 示例二:会议记录结构化
场景: 把口语化的会议记录整理成正式的 Markdown 文档
提示词(prompt.txt):
你是一名专业的会议记录整理助手。
请将以下会议记录内容整理成标准的 Markdown 格式,包含:
1. 会议主题(一级标题)
2. 参会人员(如有提及)
3. 主要议题(二级标题,每个议题单独列出)
4. 决议事项(使用 - [ ] 任务清单格式)
5. 后续跟进事项(标注责任人和截止日期,如有)
语言要正式、简洁,避免口语化表达。
📌 示例三:信息提取与分类
场景: 从一段文字中提取关键信息并分类整理
提示词(prompt.txt):
你是一名信息提取专家。
请从用户提供的文本中提取以下信息,整理成 Markdown 格式:
- **人物**:文中提到的所有人名及其角色
- **地点**:文中提到的所有地名
- **时间**:文中提到的所有时间节点
- **事件**:主要发生的事情(用简洁的语言概括)
- **数据**:文中出现的所有数字和统计数据
每类信息用二级标题(##)分隔,内容用无序列表(-)展示。
💡 提示词编写技巧
九、常见问题与排查
❓ Q1:点击「测试接口」失败,怎么办?
逐步排查:
检查 API 地址:确认没有拼写错误,末尾不要加
/检查 API Key:复制时不要带空格或换行符
检查模型名称:模型名要和服务商文档一致,大小写敏感
检查网络:确认电脑能访问该 AI 服务地址(可能需要代理)
检查余额:API Key 对应的账号是否还有调用余额
❓ Q2:加载文件后列表是空的?
可能原因:
TXT 文件夹路径选择错误,确认文件夹内确实有
.txt文件所有 TXT 都在「已完成」子文件夹里(已处理完毕)
文件扩展名不是
.txt(比如是.TXT大写,Windows 上一般没问题;macOS 需注意)
❓ Q3:某个文件一直显示「失败」?
排查步骤:
打开软件根目录下的
error.log文件,找到该文件的错误信息常见错误及解决方法:
❓ Q4:生成的 MD 文件内容不符合预期?
解决思路:
在配置页点击「预览提示词」,确认提示词内容正确加载
根据「提示词编写指南」优化提示词,让指令更具体
尝试更换更强的 AI 模型(如从 gpt-3.5-turbo 换为 gpt-4o)
检查 TXT 文件内容是否完整、无乱码
❓ Q5:处理速度很慢,怎么提速?
增大并发数(配置页或操作页调整)
使用响应速度更快的 AI 接口
提示词不要过于复杂,减少 AI 的输出长度
⚠️ 并发数不宜设置过大,否则容易触发 AI 接口的频率限制(HTTP 429 错误)
❓ Q6:TXT 文件已经被移到「已完成」,但 MD 文件没有生成?
可能是 MD 文件写入失败后才移动了 TXT,请查看 error.log 确认错误原因。
实际上软件的逻辑是:先写入 MD 成功,再移动 TXT。如果 MD 写入失败,TXT 不会被移动,文件状态会显示为「失败」。
十、注意事项与使用建议
🔐 安全建议
不要把 API Key 分享给他人,也不要存放在公开的位置
提示词文件中不要包含敏感信息(如密码、个人隐私等)
📁 文件夹管理建议
推荐的文件夹结构:
D:\AI处理项目\
├── 待处理\ ← TXT 文件夹(输入)
│ ├── 文件A.txt
│ ├── 文件B.txt
│ └── 已完成\ ← 自动创建,存放处理完的 TXT
├── 输出MD\ ← MD 输出文件夹
└── prompt.txt ← 提示词文件
📝 处理前检查清单
在点击「开始」之前,建议确认以下几项:
AI 接口测试通过(绿色提示)
提示词文件已选择并预览确认
TXT 文件夹路径正确,文件列表已加载
MD 输出文件夹路径正确(与 TXT 文件夹不同)
并发数设置合理(初次使用建议设为 1 或 2)
先用 1~2 个文件测试,确认效果满意
📊 大批量处理建议
一次处理超过 50 个文件时,建议并发数设为 2~4
长时间批处理时建议关闭屏幕保护,避免系统进入休眠
处理完成后检查
error.log,处理失败的文件可重新加载处理
附录:软件目录结构说明
软件根目录/
├── 96.根据TXT文档内容与提示词ai生成md文档.exe ← 主程序
├── config.json ← 配置文件(软件自动读写,无需手动修改)
└── error.log ← 错误日志(处理失败时查看)
💡
config.json会自动保存你的 AI 接口配置、文件夹路径等设置,下次打开软件无需重新填写。
如有问题,请查看 error.log 文件获取详细错误信息。*
