

👋 软件是做什么的?
AI识别手写PDF内容转Markdown 是一款桌面端工具,主要用来把 手写内容 PDF、扫描版 PDF、图片型 PDF 交给 AI 识别,再整理成便于编辑、复制、保存的 Markdown(.md) 文档。
它特别适合下面这些场景:
学生整理笔记
把手写课堂笔记 PDF 转成可编辑文字
老师整理资料
把扫描讲义、练习册、手写批注整理成电子文档
办公归档
把历史纸质资料、扫描文件转成方便检索的文本
知识沉淀
把原本只能“看图”的 PDF,变成可搜索、可复制、可继续加工的 Markdown 文档
简单理解就是:
📄 把“看起来像图片的 PDF” → 变成“可以继续编辑的 Markdown 文本”。
✨ 软件能帮你做什么?
本软件的完整流程大致如下:
读取你选择的 PDF 文件夹
逐个处理 PDF 文件
先把 PDF 每一页转换成图片
再逐页调用你配置好的 AI 接口进行识别
把识别结果按页写入同名
.md文件每页识别成功后自动删除已经处理完的图片
全部完成后自动删除该 PDF 对应的图片文件夹
最后把已完成的 PDF 自动移动到同目录下的
已完成文件夹中
这样做的好处是:
识别结果清晰
处理过程可追踪
失败后方便继续重试
完成后的文件自动归档,不容易重复处理
🖥 软件界面说明
软件主要分为 3 个页面:
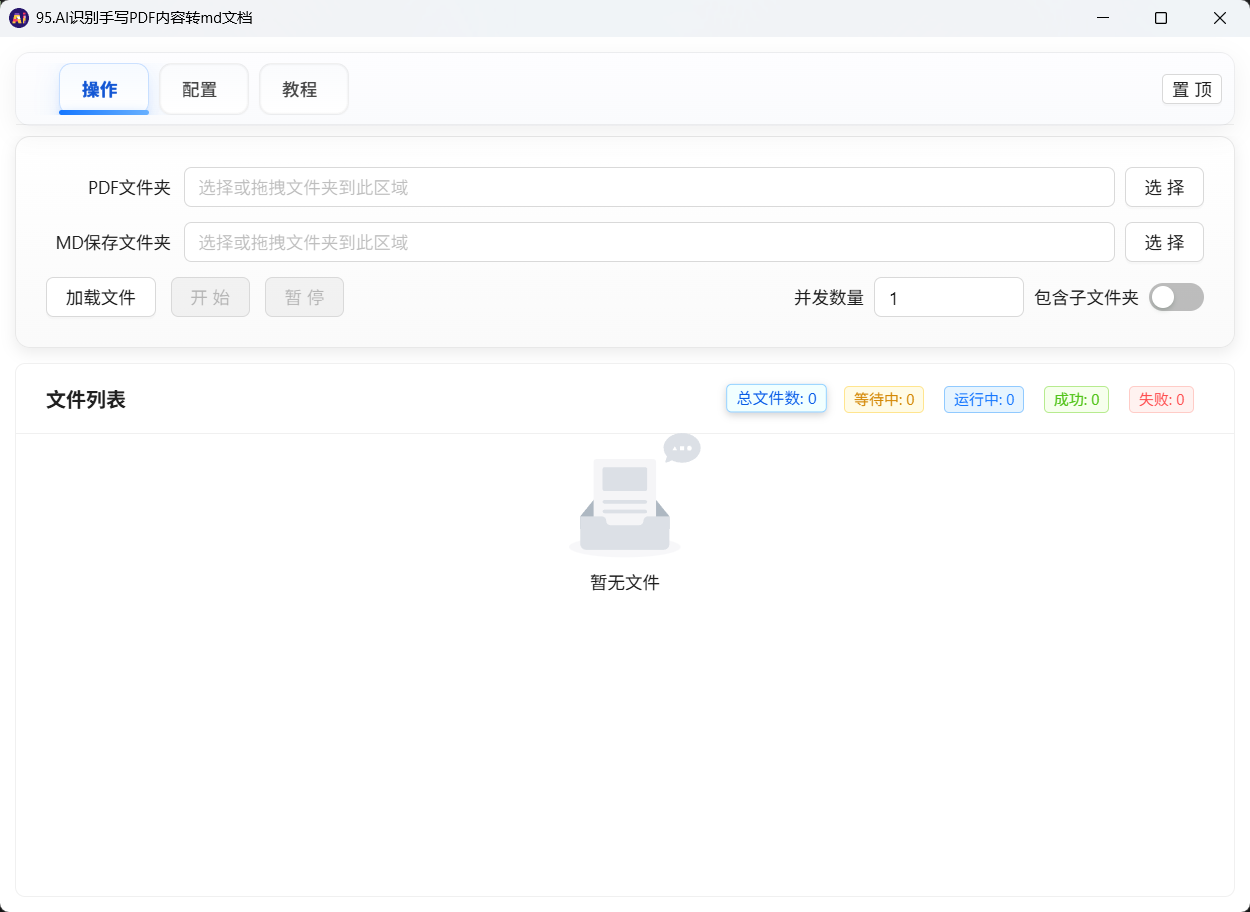
1. 操作页
这是你最常用的页面,主要负责:
选择 PDF 文件夹
加载文件
选择 Markdown 输出目录
设置并发数量
开始批量处理
查看每个 PDF 的处理状态和进度
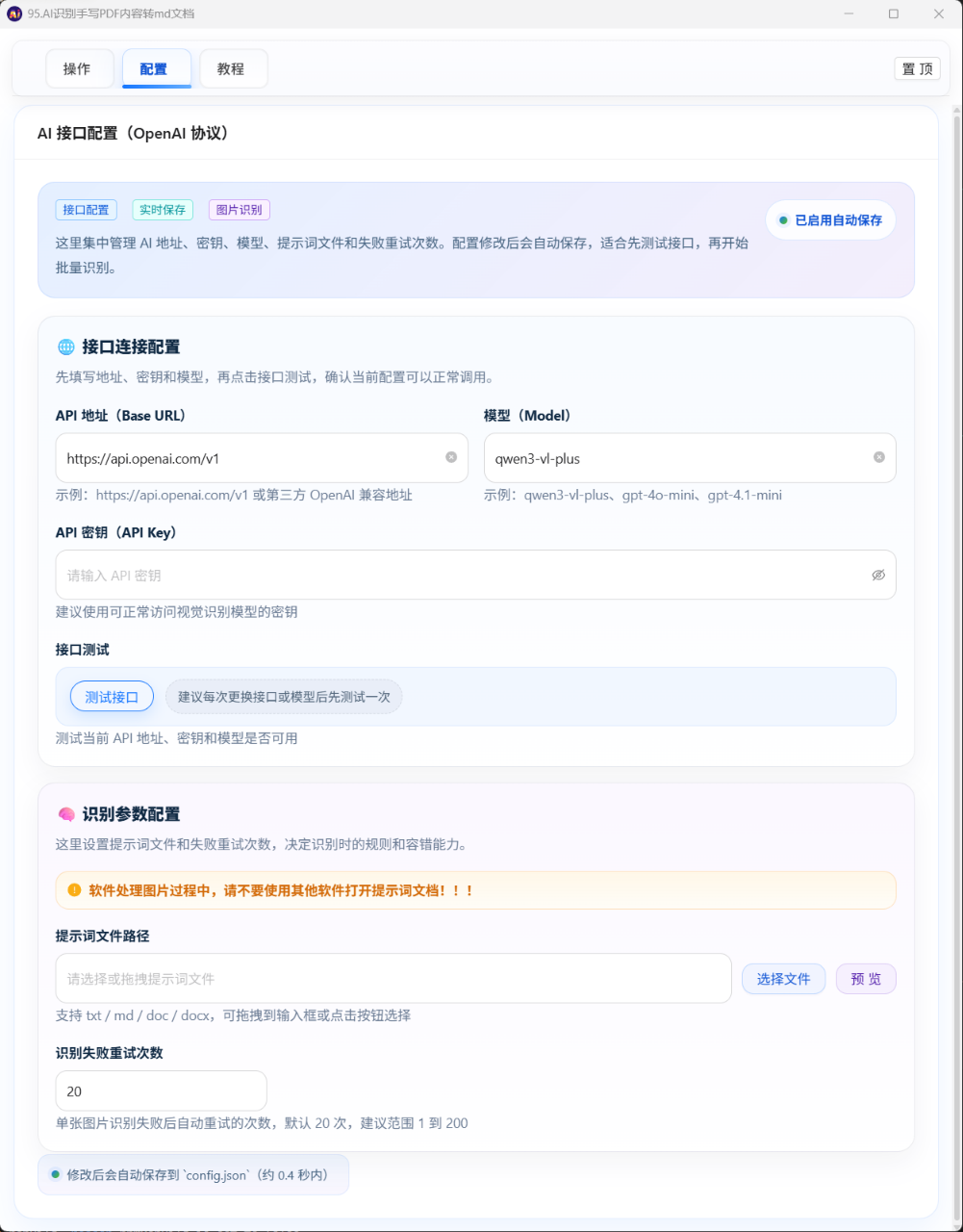
2. 配置页
这个页面主要负责填写 AI 接口相关信息:
AI 地址(Base URL)API Key模型名称提示词文件路径
另外你还可以:
点击按钮选择提示词文件
拖拽提示词文件到输入框
预览提示词文件内容
测试 AI 接口是否可用
3. 教程页
这里主要用于:
查看软件介绍
查看新手使用说明
复制作者微信进行反馈
打开更详细的教程页面
🚀 第一次使用怎么做?
如果你是第一次使用,建议严格按下面步骤来:
第一步:准备 PDF 文件
请先把你要处理的 PDF 整理到一个文件夹中。
例如:
D:\待处理PDF
├─ 语文笔记.pdf
├─ 数学作业.pdf
└─ 英语手写讲义.pdf建议:
一个文件夹里尽量放同一批次的 PDF
文件名尽量简单清楚
不要把无关文件混在里面
第二步:准备 Markdown 输出文件夹
再准备一个用来保存识别结果的文件夹。
例如:
D:\识别结果处理完成后,每个 PDF 会生成一个同名的 .md 文件。
例如:
D:\识别结果
├─ 语文笔记.md
├─ 数学作业.md
└─ 英语手写讲义.md第三步:准备提示词文件
提示词文件就是你希望 AI 按什么方式识别内容的一段说明。
软件支持以下格式:
.txt.md.doc.docx
一个简单示例:
请识别图片中的全部文字内容。
如果是手写内容,请尽量保持原意,不要随意补充不存在的内容。
请按自然段整理输出。
如果有标题,请保留标题层级。
如果有表格,请尽量转换成 Markdown 表格。建议:
提示词尽量明确
不要写得过于含糊
如果你的内容偏数学、公式、表格、试卷,可以专门写更有针对性的提示词
第四步:配置 AI 接口
打开软件后,进入 配置页,填写下面内容:
1)AI 地址
通常是兼容 OpenAI 接口格式的地址,例如:
https://api.example.com/v1请注意:
地址必须以
http://或https://开头一般不要把
/chat/completions手动写进去,软件会自动拼接
2)API Key
填写你的 AI 平台提供的密钥。
示例:
sk-xxxxxxxxxxxxxxxx3)模型名称
填写你要调用的模型,例如:
gpt-4o-mini或者你实际平台提供的模型名。
4)提示词文件路径
选择你准备好的提示词文件。
填写完成后,建议点击 测试接口 按钮确认:
地址是否正确
Key 是否有效
模型是否可用
▶ 如何开始批量处理?
完成配置后,回到 操作页,按顺序操作:
1)选择 PDF 文件夹
选择你准备好的待处理目录,例如:
D:\待处理PDF2)点击“加载文件”
软件会把目录中的 PDF 列表加载到表格里。
注意:
已经移动到
已完成文件夹中的 PDF,不会再次被加载这样可以避免重复处理
3)选择 Markdown 保存文件夹
例如:
D:\识别结果4)设置并发数量
并发数量决定“后续识别阶段”同时处理几个 PDF。
建议:
新手建议先从 1 或 2 开始
如果你的 AI 接口稳定、电脑性能较好,可以逐步提高
PDF 转图片阶段目前已经做了串行控制,不会同时多份 PDF 一起疯狂读写硬盘
5)点击“开始处理”
之后软件会自动开始执行。
你可以在表格中看到每个文件的:
当前状态
当前进度
是否成功
是否失败
🔄 软件处理时会发生什么?
为了让你更容易理解,这里用一个例子说明。
假设你处理的是:
D:\待处理PDF\数学作业.pdf软件大致会这样做:
阶段 1:准备处理
软件先检查:
PDF 路径是否存在
输出目录是否存在
提示词文件是否存在
AI 配置是否完整
阶段 2:PDF 转图片
软件会把 PDF 逐页转成图片,例如:
D:\待处理PDF\数学作业\1.png
D:\待处理PDF\数学作业\2.png
D:\待处理PDF\数学作业\3.png阶段 3:AI 逐页识别
软件会按页调用 AI 接口进行识别。
识别结果会写入:
D:\识别结果\数学作业.md写入格式类似:
## 第1页
第一页的识别内容
## 第2页
第二页的识别内容阶段 4:边识别边清理
每当一页识别成功后:
对应图片会被删除
这样可以减少磁盘占用
阶段 5:全部完成后归档
当所有页面都成功识别后:
图片文件夹会被删除
原 PDF 会被移动到:
D:\待处理PDF\已完成\数学作业.pdf如果 已完成 文件夹不存在,软件会自动创建。
⏸ 可以暂停吗?
可以。
如果你正在批量处理多个 PDF,软件支持暂停与继续。
适合这些情况:
你临时不想继续调用 AI 接口
你想暂停观察当前识别结果
你希望在网络恢复后再继续
暂停后:
当前批处理会停下来等待
继续后会从合适的位置恢复
♻ 处理中断了怎么办?
不用太紧张,软件已经考虑了断点续跑的场景。
情况 1:PDF 已经转成图片,但还没识别完
如果:
PDF 对应图片文件夹还在
输出目录里已经有同名
.md文件
那么软件会判断为 断点续跑。
也就是说:
不会重复转图
会直接从现有图片继续识别
这对以下场景非常有用:
中途断电
AI 接口临时报错
软件被关闭
网络异常
❌ AI 识别失败怎么办?
软件已经内置自动重试机制。
目前每张图片:
最多可重试 100 次
并带有逐步增加的等待时间
这样做的好处是:
接口偶发失败时,更容易自动恢复
避免连续高频轰炸接口
提高长任务成功率
如果最终还是失败:
当前 PDF 会处理失败
错误会尽量详细写入
error.log
日志里会尽量包含:
图片路径
接口地址
模型名称
请求摘要
HTTP 状态码
AI 返回原文
错误信息
这样方便你排查到底是:
Key 问题
模型问题
接口限流
网络异常
返回格式异常
🧾 error.log 在哪里?有什么用?
软件运行时会把重要错误写入项目目录下的:
error.log它主要用于排查问题。
如果你遇到:
某个 PDF 一直失败
接口一直报错
识别中途停止
教程页/操作页异常
都建议先查看这个文件。
如果需要联系作者反馈问题,最好把:
出问题的 PDF 文件名
你填写的 AI 地址
error.log中相关时间段内容
一起发过去,这样定位会更快。
📦 已完成 文件夹是什么?
当一个 PDF 全部处理完成后,软件会自动把它移到同目录下的 已完成 文件夹。
例如:
处理前:
D:\待处理PDF
├─ 语文笔记.pdf
├─ 数学作业.pdf处理后:
D:\待处理PDF
├─ 已完成
│ ├─ 语文笔记.pdf
│ └─ 数学作业.pdf这么做的好处:
避免重复处理
待处理文件和已处理文件分开,更清楚
再次加载文件时,软件会自动忽略
已完成目录中的 PDF
如果出现同名冲突,软件会自动改名,例如:
数学作业-1.pdf
数学作业-2.pdf🧠 小白用户最推荐的使用方式
如果你不熟悉这类工具,建议你这样用:
推荐方案
并发数量先设为
1先拿
1~2 个 PDF测试确认识别效果满意后,再批量处理更多文件
提示词尽量先写简单明确
为什么这样更稳?
因为这样更容易发现:
提示词是否适合你的资料
AI 模型是否识别得准
接口是否稳定
输出格式是不是你想要的
📝 一个完整使用示例
下面给你一个从头到尾的实际例子。
你的文件准备
待处理目录:
E:\学习资料\手写PDF
├─ 历史笔记.pdf
├─ 化学错题.pdf输出目录:
E:\学习资料\Markdown结果提示词文件内容:
请识别图片中的所有文字内容。
保持原意,不要编造不存在的内容。
如果有标题,请保留层级。
如果有列表,请整理成清晰的 Markdown 列表。操作步骤
打开软件
进入配置页
填写 AI 地址、API Key、模型
选择提示词文件
点击测试接口
回到操作页
选择
E:\学习资料\手写PDF点击加载文件
选择
E:\学习资料\Markdown结果并发数量设为
1点击开始处理
最终你会得到
输出目录:
E:\学习资料\Markdown结果
├─ 历史笔记.md
└─ 化学错题.md原 PDF 会被归档到:
E:\学习资料\手写PDF\已完成
├─ 历史笔记.pdf
└─ 化学错题.pdf⚠ 使用时的注意事项
1)API Key 不要随意泄露
API Key 属于敏感信息,请不要截图公开,不要发给陌生人。
2)先测试接口,再跑批量
如果接口本身不可用,直接开始批量处理只会浪费时间。
3)提示词会直接影响识别效果
同一个 PDF,换一个提示词,识别结果可能差很多。
4)不是所有手写都能 100% 完美识别
以下情况可能影响识别质量:
字迹非常潦草
图片太模糊
页面歪斜严重
有大量涂改、阴影、污点
5)建议保留原始 PDF
虽然软件会自动归档已完成 PDF,但仍建议你保留原始资料备份。
🛠 常见问题答疑
Q1:为什么加载文件后看不到某些 PDF?
可能原因:
文件不在你选中的目录里
文件被放进了
已完成文件夹文件扩展名不在支持范围内
Q2:为什么一直显示失败?
常见原因:
AI 地址填错
API Key 无效
模型名填错
接口限流或余额不足
网络不稳定
建议:
先点“测试接口”
再查看
error.log
Q3:为什么会生成图片文件夹?
因为软件需要先把 PDF 每一页转成图片,再交给 AI 识别。
Q4:识别到一半软件关闭了怎么办?
如果图片文件夹和 .md 文件还在,重新开始后通常可以继续处理,不一定要从头来。
Q5:为什么处理很慢?
可能原因:
PDF 页数很多
图片较大
AI 接口响应慢
并发设置较低
网络较慢
💡 提示词示例参考
通用识别提示词
请识别图片中的全部文字内容。
保持原文含义,不要编造不存在的内容。
按自然段整理输出。
如有标题,请保留层级。
输出使用 Markdown 格式。适合手写笔记的提示词
请识别这页手写笔记中的所有内容。
如果有标题、小标题、编号、列表,请尽量按原结构整理。
保持原意,不要自行扩写。
输出为易读的 Markdown 格式。适合试卷/题目的提示词
请识别图片中的题目内容、题号、选项和解析。
尽量保持题目结构完整。
如果有多级编号,请保留层级。
输出为 Markdown。📬 遇到问题怎么办?
如果你在使用过程中遇到问题,可以:
先查看教程页说明
再查看
error.log准备好报错信息与文件名
通过教程页中的作者微信联系反馈
建议反馈时说明:
你在做什么操作
哪个 PDF 出问题
问题是稳定复现还是偶发
error.log里对应的报错内容
🎯 最后给小白用户的建议
如果你是第一次接触这类 AI 识别软件,请记住下面这几句话:
先少量测试,再大量处理
先确认提示词,再追求速度
先看 error.log,再判断是不是软件问题
并发不要一开始就开太大
已完成文件会自动归档,不用担心重复处理
